 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBench: A Comprehensive Benchmark on Memory Capability for Video World Models
May 30, 2026Recent advancements in video-based world models have demonstrated an unprecedented ability to synthesize high-fidelity visual sequences. However, a fundamental gap persists between visually plausible video generation and the functional requirements of a world model, particularly in maintaining a stable and reasonable internal state over extended temporal horizons. While existing benchmarks primarily emphasize visual quality, motion coherence, and text-video alignment, they largely overlook memory, the core capability of a world model to preserve consistency across long-term horizons and complex interactions. To address this gap, we present \textbf{MBench}, a comprehensive benchmark dedicated to quantifying and evaluating the memory capability of video world models. We systematically decompose the memory capability of video world models into three hierarchical and complementary core dimensions: entity consistency, environment consistency, and causal consistency, which are further refined into 12 quantifiable sub-dimensions for comprehensive characterization of long-term memory. Our benchmark is built upon rigorously curated real-captured long videos, and evaluated by rule-based quantitative matrices and VLM to enable objective and comprehensive consistency assessment. Extensive evaluations of mainstream state-of-the-art video world models reveal critical systemic limitations of existing methods in long-term state retention, providing a standardized benchmark and clear research direction to advance the field.
AnyMo: Scaling Any-Modality Conditional Motion Generation with Masked Modeling
May 28, 2026Conditional human motion generation remains a fundamental challenge in computer vision and robotics. Despite significant progress, current methods are often constrained by fixed modality configurations and task-specific architectures, leaving cross-modal interactions and the scaling laws of multimodal-conditioned synthesis largely underexplored. A key bottleneck is the scarcity of large-scale modality-aligned motion data, limiting generalization across diverse control signals. In this work, we introduce OmniHuMo, a large-scale, high-quality dataset comprising over 5,000 hours of motion and 3.2 million sequences with precisely aligned multimodal annotations (e.g., text, speech, music, and trajectory). Leveraging OmniHuMo, we propose AnyMo, a unified multimodal framework combining a Residual FSQ-based motion tokenizer with a scalable masked modeling transformer, enabling high-quality motion synthesis under arbitrary modality combinations. Extensive experiments show that AnyMo achieves high-fidelity synthesis while offering flexible control over both spatial and stylistic attributes.
OmniHuman: A Large-scale Dataset and Benchmark for Human-Centric Video Generation
Apr 20, 2026Recent advancements in audio-video joint generation models have demonstrated impressive capabilities in content creation. However, generating high-fidelity human-centric videos in complex, real-world physical scenes remains a significant challenge. We identify that the root cause lies in the structural deficiencies of existing datasets across three dimensions: limited global scene and camera diversity, sparse interaction modeling (both person-person and person-object), and insufficient individual attribute alignment. To bridge these gaps, we present OmniHuman, a large-scale, multi-scene dataset designed for fine-grained human modeling. OmniHuman provides a hierarchical annotation covering video-level scenes, frame-level interactions, and individual-level attributes. To facilitate this, we develop a fully automated pipeline for high-quality data collection and multi-modal annotation. Complementary to the dataset, we establish the OmniHuman Benchmark (OHBench), a three-level evaluation system that provides a scientific diagnosis for human-centric audio-video synthesis. Crucially, OHBench introduces metrics that are highly consistent with human perception, filling the gaps in existing benchmarks by providing a comprehensive diagnosis across global scenes, relational interactions, and individual attributes.
Identity as Presence: Towards Appearance and Voice Personalized Joint Audio-Video Generation
Mar 18, 2026Recent advances have demonstrated compelling capabilities in synthesizing real individuals into generated videos, reflecting the growing demand for identity-aware content creation. Nevertheless, an openly accessible framework enabling fine-grained control over facial appearance and voice timbre across multiple identities remains unavailable. In this work, we present a unified and scalable framework for identity-aware joint audio-video generation, enabling high-fidelity and consistent personalization. Specifically, we introduce a data curation pipeline that automatically extracts identity-bearing information with paired annotations across audio and visual modalities, covering diverse scenarios from single-subject to multi-subject interactions. We further propose a flexible and scalable identity injection mechanism for single- and multi-subject scenarios, in which both facial appearance and vocal timbre act as identity-bearing control signals. Moreover, in light of modality disparity, we design a multi-stage training strategy to accelerate convergence and enforce cross-modal coherence. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our webpage: \href{https://chen-yingjie.github.io/projects/Identity-as-Presence}{Identity-as-Presence}.
Trend-Aware Supervision: On Learning Invariance for Semi-Supervised Facial Action Unit Intensity Estimation
Mar 11, 2025



With the increasing need for facial behavior analysis, semi-supervised AU intensity estimation using only keyframe annotations has emerged as a practical and effective solution to relieve the burden of annotation. However, the lack of annotations makes the spurious correlation problem caused by AU co-occurrences and subject variation much more prominent, leading to non-robust intensity estimation that is entangled among AUs and biased among subjects. We observe that trend information inherent in keyframe annotations could act as extra supervision and raising the awareness of AU-specific facial appearance changing trends during training is the key to learning invariant AU-specific features. To this end, we propose \textbf{T}rend-\textbf{A}ware \textbf{S}upervision (TAS), which pursues three kinds of trend awareness, including intra-trend ranking awareness, intra-trend speed awareness, and inter-trend subject awareness. TAS alleviates the spurious correlation problem by raising trend awareness during training to learn AU-specific features that represent the corresponding facial appearance changes, to achieve intensity estimation invariance. Experiments conducted on two commonly used AU benchmark datasets, BP4D and DISFA, show the effectiveness of each kind of awareness. And under trend-aware supervision, the performance can be improved without extra computational or storage costs during inference.
Perception-as-Control: Fine-grained Controllable Image Animation with 3D-aware Motion Representation
Jan 09, 2025



Motion-controllable image animation is a fundamental task with a wide range of potential applications. Recent works have made progress in controlling camera or object motion via various motion representations, while they still struggle to support collaborative camera and object motion control with adaptive control granularity. To this end, we introduce 3D-aware motion representation and propose an image animation framework, called Perception-as-Control, to achieve fine-grained collaborative motion control. Specifically, we construct 3D-aware motion representation from a reference image, manipulate it based on interpreted user intentions, and perceive it from different viewpoints. In this way, camera and object motions are transformed into intuitive, consistent visual changes. Then, the proposed framework leverages the perception results as motion control signals, enabling it to support various motion-related video synthesis tasks in a unified and flexible way. Experiments demonstrate the superiority of the proposed framework. For more details and qualitative results, please refer to our project webpage: https://chen-yingjie.github.io/projects/Perception-as-Control.
I2CANSAY:Inter-Class Analogical Augmentation and Intra-Class Significance Analysis for Non-Exemplar Online Task-Free Continual Learning
Apr 21, 2024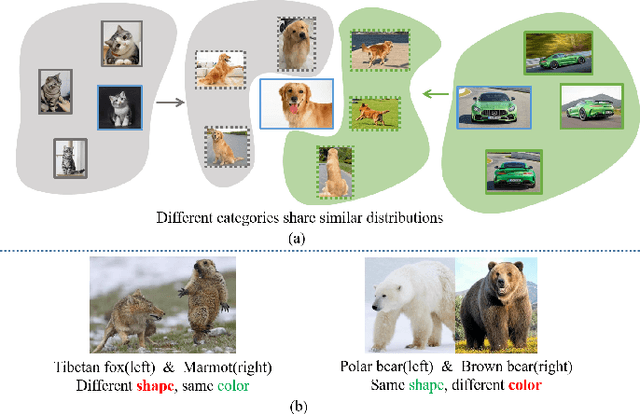
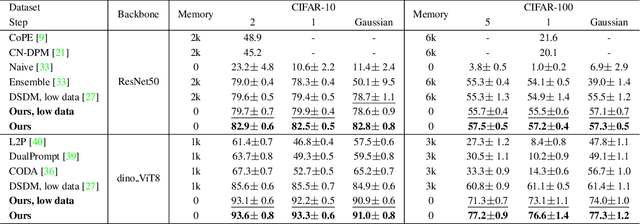
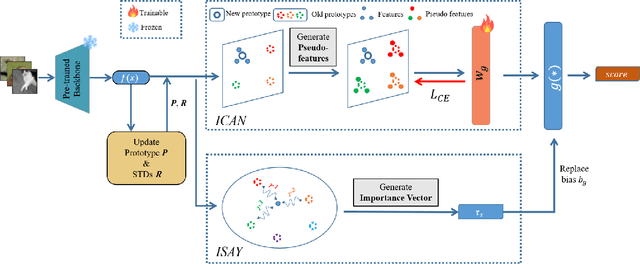
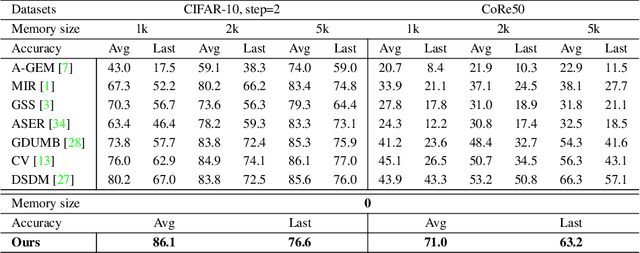
Online task-free continual learning (OTFCL) is a more challenging variant of continual learning which emphasizes the gradual shift of task boundaries and learns in an online mode. Existing methods rely on a memory buffer composed of old samples to prevent forgetting. However,the use of memory buffers not only raises privacy concerns but also hinders the efficient learning of new samples. To address this problem, we propose a novel framework called I2CANSAY that gets rid of the dependence on memory buffers and efficiently learns the knowledge of new data from one-shot samples. Concretely, our framework comprises two main modules. Firstly, the Inter-Class Analogical Augmentation (ICAN) module generates diverse pseudo-features for old classes based on the inter-class analogy of feature distributions for different new classes, serving as a substitute for the memory buffer. Secondly, the Intra-Class Significance Analysis (ISAY) module analyzes the significance of attributes for each class via its distribution standard deviation, and generates the importance vector as a correction bias for the linear classifier, thereby enhancing the capability of learning from new samples. We run our experiments on four popular image classification datasets: CoRe50, CIFAR-10, CIFAR-100, and CUB-200, our approach outperforms the prior state-of-the-art by a large margin.
LiDAR-Forest Dataset: LiDAR Point Cloud Simulation Dataset for Forestry Application
Feb 15, 2024


The popularity of LiDAR devices and sensor technology has gradually empowered users from autonomous driving to forest monitoring, and research on 3D LiDAR has made remarkable progress over the years. Unlike 2D images, whose focused area is visible and rich in texture information, understanding the point distribution can help companies and researchers find better ways to develop point-based 3D applications. In this work, we contribute an unreal-based LiDAR simulation tool and a 3D simulation dataset named LiDAR-Forest, which can be used by various studies to evaluate forest reconstruction, tree DBH estimation, and point cloud compression for easy visualization. The simulation is customizable in tree species, LiDAR types and scene generation, with low cost and high efficiency.
Towards Unbiased Label Distribution Learning for Facial Pose Estimation Using Anisotropic Spherical Gaussian
Aug 19, 2022
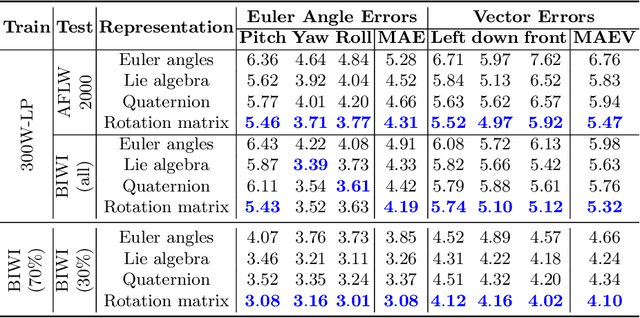
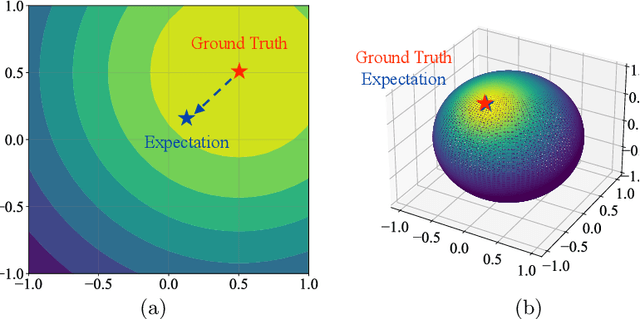
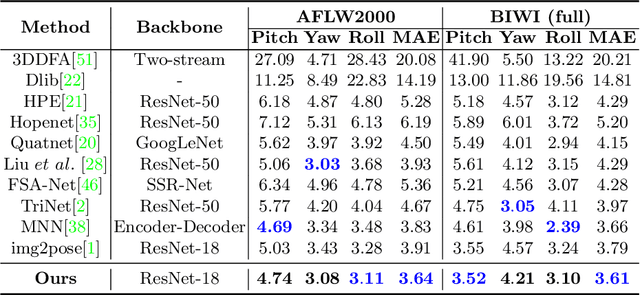
Facial pose estimation refers to the task of predicting face orientation from a single RGB image. It is an important research topic with a wide range of applications in computer vision. Label distribution learning (LDL) based methods have been recently proposed for facial pose estimation, which achieve promising results. However, there are two major issues in existing LDL methods. First, the expectations of label distributions are biased, leading to a biased pose estimation. Second, fixed distribution parameters are applied for all learning samples, severely limiting the model capability. In this paper, we propose an Anisotropic Spherical Gaussian (ASG)-based LDL approach for facial pose estimation. In particular, our approach adopts the spherical Gaussian distribution on a unit sphere which constantly generates unbiased expectation. Meanwhile, we introduce a new loss function that allows the network to learn the distribution parameter for each learning sample flexibly. Extensive experimental results show that our method sets new state-of-the-art records on AFLW2000 and BIWI datasets.
On Mitigating Hard Clusters for Face Clustering
Jul 25, 2022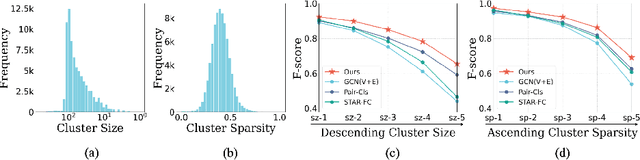
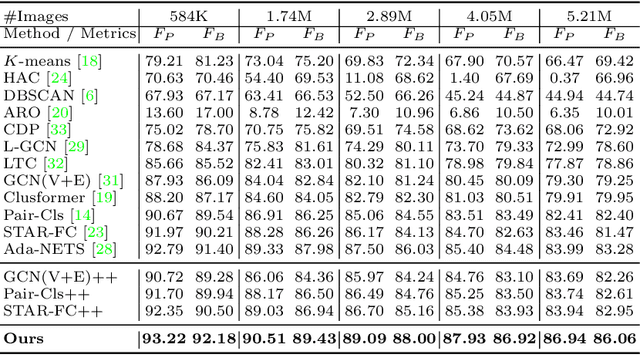
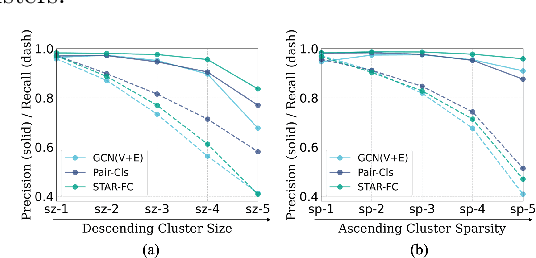
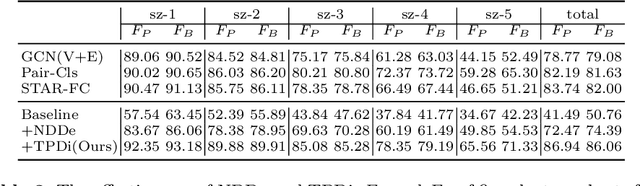
Face clustering is a promising way to scale up face recognition systems using large-scale unlabeled face images. It remains challenging to identify small or sparse face image clusters that we call hard clusters, which is caused by the heterogeneity, \ie, high variations in size and sparsity, of the clusters. Consequently, the conventional way of using a uniform threshold (to identify clusters) often leads to a terrible misclassification for the samples that should belong to hard clusters. We tackle this problem by leveraging the neighborhood information of samples and inferring the cluster memberships (of samples) in a probabilistic way. We introduce two novel modules, Neighborhood-Diffusion-based Density (NDDe) and Transition-Probability-based Distance (TPDi), based on which we can simply apply the standard Density Peak Clustering algorithm with a uniform threshold. Our experiments on multiple benchmarks show that each module contributes to the final performance of our method, and by incorporating them into other advanced face clustering methods, these two modules can boost the performance of these methods to a new state-of-the-art. Code is available at: https://github.com/echoanran/On-Mitigating-Hard-Clusters.